Article 2 : Création d'un translateur.
Pierre Chifflier - pollux@wzdftpd.net, David Odin - dindinx@gimp.org
Comme nous l'avons vu lors du précédente article de cette série, la notion de translateur est un des thèmes centraux de GNU/Hurd. Aujourd'hui nous allons décortiquer ce qui se cache derrière ce mot et voir comment un simple utilisateur est capable de créer un tel objet.
Dans un système comme le Hurd, les fichiers sont utilisés pour pratiquement tout. Déjà sous
GNU/Linux, on trouvait un générateur de nombres aléatoires dans /dev/urandom ou
des informations sur les processeurs dans /proc/cpuinfo. Mais sous GNU/Linux, ces
fichiers spéciaux ne pouvait être créé que par l'utilisateur root, et
avait un comportement forcément assez limité (un fichier comme cpuinfo n'existe que
dans un système de fichier particulier, par exemple).
Le Hurd va plus loin dans cette idée grâce à la notion de translateurs. Un translateur
est un programme (service) qu'un utilisateur (pas forcément root) va associer à un fichier ou
un répertoire pour lui donner un comportement particulier. Ainsi, les fichiers dans
/devcachent tous des translateurs, une partition montée est simplement un
répertoire (le point de montage) associé à un translateur capable de gérer un système de
fichier (ext2 par exemple). Et même l'interface réseau (pfinet) est un translateur particulier.
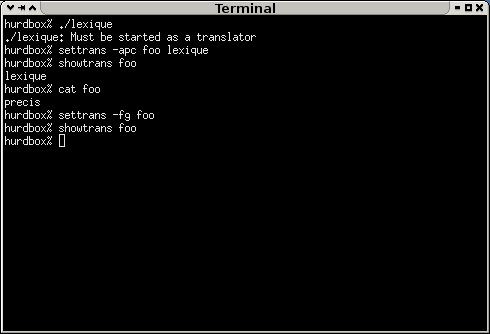
L'association entre un fichier ou un répertoire et un translateur est effectué à l'aide de la
commande settrans et il est possible de connaître l'état d'un translateur passif
à l'aide de la commande showtrans, et l'état d'un translateur actif avec la
commande fsysopt.
Comme nous le verrons dans la seconde partie de cet article, il est assez facile de créer un translateur donnant un rôle particulier à un fichier. Mais avant de se lancer dans la création d'un tel outil, il faut se pencher sur la notion de ports.
Dans Mach, les serveurs communiquent en envoyant des messages à travers des "ports", sortes de files de messages. Ces ports disposent de permissions: la réception de messages est associée à une seule tâche, alors que plusieurs tâches peuvent envoyer des messages.
L'utilisation de ces messages est assez semblable à l'utilisation des RPC[1] sous linux. L'envoi de messages ressemble à un appel de fonction, mais en pratique le message transite par Mach qui le redirige vers la tâche associée. L'idée n'est pas limitée à une seule machine, le message pourrait très bien être envoyé sur le réseau à une autre machine de manière transparente.
Pour obtenir un port sur un serveur, il suffit d'explorer le système de fichiers, et d'utiliser la fonction hurd_file_name_lookup qui renvoie un droit d'envoi sur le port du serveur associé au noeud du système de fichiers (si on dispose des droits suffisants sur le fichier). Ce concept fonctionne bien puisque dans Hurd il existe toujours un système de fichiers.
Par exemple, voici comment utiliser le fichier /servers/password pour obtenir un port sur le serveur de mots de passe :
mach_port_t identity;
mach_port_t pwserver;
kern_return_t err;
pwserver = hurd_file_name_lookup
("/servers/password");
err = password_check_user (pwserver,
0 /* root */, "supass",
&identity);
Le premier appel de fonction permet de récupérer un descripteur pour le fichier
"/servers/password", qui se trouve être associé au translateur
permettant de tester l'identité des utilisateurs. Le second appel vérifie
l'identité de l'utilisateur root en s'assurant que son mot de passe est bien
"supass", et renvoie éventuellement un port sur son identité (qui
pourrait servir par la suite à obtenir un jeton du serveur auth,
en utilisant la fonction msg_add_auth). C'est ce que fait par exemple
la commande addauth.
Trivfs est une bibliothèque qui permet de développer rapidement un translateur simple, en général limité à un seul fichier. Dans GNU/Hurd, l'envoi de messages pour les fonctions habituelles sur un fichier sont encapsulées dans les fonctions de la bibliothèque C, qui se charge d'envoyer les messages sur les ports. Cela signifie qu'on n'implémentera pas les fonctions comme read(), mais plutôt la fonction associée au message, par exemple io_read (). Du point de vue du programme appelant, rien ne change, il suffit d'appeler la fonction read() et la libc se charge d'envoyer les messages, ce qui est un point important pour la compatibilité avec les autres systèmes !
Avec trivfs, il faudra implémenter des fonctions dont le prototype est fixé, et qui correspondent à tous les messages que pourra recevoir notre translateur. Trivfs se charge de convertir le port en une structure contenant les données associées à une instance du fichier (credentials). Cela permet de conserver des informations propres à chaque instance du translateur. La fonction read() est donc convertie en un message, que notre translateur recevra par l'intermédiaire de la fonction trivfs_S_io_read, qui décode les arguments de la RPC io_read().
Afin de pouvoir utiliser trivfs, il faut installer les paquets gnumach-dev et hurd-dev, et pour ceux qui n'auraient pas suivi le but de l'article, un compilateur (gcc).
Le translateur que nous allons implémenter aujourd'hui tiendra le rôle de lexique anglais/français. On pourra écrire un mot en anglais dans le fichier attaché, et la lecture de ce fichier fournira le mot traduit en français.
Pour faciliter la compréhension, nous avons choisi de présenter ce programme de manière évolutive : dans un premier temps, nous allons voire comment réaliser un translateur en lecture seule, ce qui posera les bases indispensables, puis nous compliquerons petit à petit pour obtenir le translateur final.
#define _GNU_SOURCE 1Cette constante doit être définie pour tout programme utilisant les bibliothèqued du Hurd. Elle doit être définie avant d'inclure les fichiers d'entête, puisqu'elle modifie légèrement leur comportement. On peut donc maintenant les inclure :
#include <stdio.h> #include <hurd/trivfs.h> #include <fcntl.h> #include <sys/mman.h> #include <error.h>Nous voici prêt à définir quelques variables globales indispensables qui indiquent le comportement général de notre translateur :
int trivfs_fstype = FSTYPE_MISC; /* translateur trivfs générique * voir /usr/include/hurd/hurd_types.h pour les valeurs possibles */ int trivfs_fsid = 0; /* doit toujours être à zéro au début */ /* comment notre fichier/translateur peut être ouvert */ int trivfs_allow_open = O_READ; /* ce que l'on a implémenté */ int trivfs_support_read = 1; int trivfs_support_write = 0; int trivfs_support_exec = 0;Puis vient le moment de déclarer nos propres variables globales :
/* Une structure pour les mots que notre lexique connaît */
struct t_lexique {
char * value;
};
struct t_lexique lexique[] = {
{ "precis\n" },
{ "biere\n" },
{ "vim\n" },
{ "hurd\n" },
{ "piscine\n" },
{ "vin\n" },
{ NULL }
};
/* le numéro du mot que le translateur renvoie lors d'un read. */
static int index = 0;
Note : on ajoute un retour à la ligne "\n" à la fin de chaque
mot uniquement pour que l'affichage soit un peu plus joli lors de nos tests
avec cat !
Les translateurs sont des programmes comme les autres, donc ils ont besoin d'une
fonction main(). Cependant, ils ne fonctionneront correctement que s'ils ont été
lancés en tant que translateurs (c'est-à-dire en spécifiant à quel noeud ils doivent
être attachés avec settrans), donc il nous faut un moyen de vérifier qu'il n'ont pas
été lancés comme d'autres programmes. Il suffit de vérifier que le programme dispose
d'un port de démarrage avec la fonction task_get_bootstrap_port, et que le
retour n'est pas MACH_PORT_NULL.
int
main (int argc, char **argv)
{
error_t err;
mach_port_t bootstrap;
struct trivfs_control *fsys;
task_get_bootstrap_port (mach_task_self (), &bootstrap);
if (bootstrap == MACH_PORT_NULL)
error (1,0, "Doit être lancé comme un translateur");
/* Réponse au parent */
err = trivfs_startup (bootstrap, 0, 0, 0, 0, 0, &fsys);
mach_port_deallocate (mach_task_self (), bootstrap);
if (err)
error (3, err, "trivfs_startup");
/* C'est parti ! */
ports_manage_port_operations_one_thread (fsys->pi.bucket, trivfs_demuxer, 0);
return 0;
}
error_t
trivfs_goaway (struct trivfs_control *cntl, int flags)
{
exit (0);
}
trivfs offre la possibilité d'appeler une fonction après certains événements, par exemple lorsque le translateur est ouvert, détruit, etc. Nous allons utiliser ces fonctions pour connaître le nombre d'octets que nous avons déjà envoyé dans les précédents appels. C'est indispensable, car la fonction read() sera toujours appelée au moins deux fois : une fois pour lire les données, et un autre appel qui indiquera la fin du fichier. Nous allons donc garder dans une structure un variable qui nous donnera combien d'octets ont été lus depuis l'ouverture du fichier attaché à notre translateur. Il faudra donc s'assurer que cette variable soit remise à zéro lors de chaque ouverture. Nous allons donc demander à trivfs d'appeler automatiquement des fonctions lors de l'ouverture et lors de la fermeture du fichier.
On déclare deux fonctions de rappel (hooks) à partir des prototypes définis dans le fichier /usr/include/hurd/trivfs.h dont voici un extrait :
/* If this variable is set, it is called every time a new peropen structure is created and initialized. */ error_t (*trivfs_peropen_create_hook)(struct trivfs_peropen *) = open_hook; /* If this variable is set, it is called every time a peropen structure is about to be destroyed. */ void (*trivfs_peropen_destroy_hook) (struct trivfs_peropen *) = close_hook;
A l'ouverture du translateur, un hook est appelé avec une structure trivfs_peropen en paramètre. Cette structure contient un champ que nous pouvons utiliser pour stocker les valeurs à conserver tant que le translateur reste ouvert par un processus. Nous allons y stocker une structure struct open définie au début du programme, qui contiendra l'offset des données lues :
/* On gardera dans cette structure ce qui nous permet de
décrire l'état d'un descripteur de fichier : l'offset
depuis le début du fichier. */
struct open
{
off_t offs;
};
static error_t
open_hook (struct trivfs_peropen *peropen)
{
struct open *op = malloc (sizeof (struct open));
if (op == NULL)
return ENOMEM;
/* Initialisation de l'offset. */
op->offs = 0;
peropen->hook = op;
return 0;
}
Dans le hook pour la fonction close(), nous n'avons pas
grand chose à faire si ce n'est libérer la mémoire que l'on a alloué dans celui
pour la fonction open() :
static void
close_hook (struct trivfs_peropen *peropen)
{
free (peropen->hook);
}
Maintenant que nous avons réglé le problème des hook, nous pouvons passer à la réalisation des fonctions vraiment utiles.
Notre première version de la fonction stat() se contentera du strict minimum : indiquer que notre translateur est un fichier, et lui donner les permissions suffisantes pour être lu :
void trivfs_modify_stat (struct trivfs_protid *cred, io_statbuf_t *st)
{
/* On a un fichier en lecture seule de 42 octets. */
st->st_mode &= ~(S_IFMT | ALLPERMS);
st->st_mode |= (S_IFREG | S_IRUSR | S_IRGRP | S_IROTH);
st->st_size = 42;
}
Sous linux, nous aurions du implémenter la fonction read(), qui prend en paramètre un descripteur de fichiers. Sous Hurd, la fonction est io_read(), et son argument principal est un port, qui agit de manière semblable. La bibliothèqueTrivfs encapsule cette fonction pour aider à décoder ses arguments, en particulier les autorisations (credentials).
Nous nous contenterons donc d'implémenter la fonction trivfs_S_io_read(). Les arguments sont les suivants:
| Type | Nom | Description |
| trivfs_protid_t | cred | informations de sécurité (credentials) |
| mach_port_t | reply | Le port où sera envoyée la réponse |
| mach_msg_type_name_t | replyPoly | les permissions sur le port pour répondre |
| data_t * | data | un pointeur sur l'endroit où écrire les données |
| mach_msg_type_number_t * | data_len | la taille des données que nous renvoyons. Au départ, cette variable contient la taille initiale allouée pour data |
| loff_t | offs | La position actuelle. Si la valeur est -1, nous utilisons la valeur que nous avons stocké |
| vm_size_t | amount | la quantité de données demandée |
Le principe est le suivant: après toutes les vérifications nécessaires pour s'assurer que la quantité de données à lire est correcte, on calcule la quantité effective de données que la fonction va renvoyer. Si le tableau passé en argument data n'est pas assez grand, il faut le réallouer. Il est important ne noter qu'il n'est pas possible d'utiliser la fonction malloc(), puisque le pointeur renvoyé serait spécifique à notre processus, alors que nous voulons le donner au processus qui effectue la lecture.
On termine la fonction en recopiant les données, en spécifiant la quantité effective lue, et en indiquant par un code de retour nul que la fonction s'est bien déroulée.
error_t
trivfs_S_io_read (
trivfs_protid_t cred,
mach_port_t reply,
mach_msg_type_name_t replyPoly,
data_t *data,
mach_msg_type_number_t *data_len,
loff_t offs,
vm_size_t amount
)
{
struct open *op;
char * value;
/* On refuse l'accès s'il n'y a pas les bons crédits ou si
* le fichier n'est pas ouvert en lecture */
if (! cred)
return EOPNOTSUPP;
else if (! (cred->po->openmodes & O_READ))
return EBADF;
/* On récupère l'offset. */
op = cred->po->hook;
if (offs == -1)
offs = op->offs;
if (index > sizeof(lexique)/sizeof(*lexique)-1)
return EINVAL;
value = lexique[index].value;
/* On récupère la quantité de données à lire, et on la corrige
* si nécessaire. */
if (offs > strlen (value))
offs = strlen (value);
if (offs + amount > strlen (value))
amount = strlen (value) - offs;
if (amount > 0)
{
/* Reallocation si besoin */
if (*data_len < amount)
*data = (data_t) mmap (0, amount, PROT_READ|PROT_WRITE,
MAP_ANON, 0, 0);
/* c'est ici que la lecture effective se passe */
memcpy ((char *) *data, value + offs, amount);
op->offs += amount;
}
*data_len = amount;
return 0;
}
Pour pouvoir écrire un "Hello, world !", on a déjà vu plus court !
La lecture des données n'est pas le seul cas ou la position peut être modifiée, le processus peut également appeler la fonction seek(). Dans notre cas, il n'est pas obligatoire de l'implémenter (il ne serait juste plus possible de modifier la position), mais il est plus cohérent de pouvoir modifier explicitement l'offset que nous stockons dans nos données privées.
/* Déplacement du pointeur de lecture/écriture */
error_t
trivfs_S_io_seek (
trivfs_protid_t cred,
mach_port_t reply,
mach_msg_type_name_t replyPoly,
loff_t offs,
int whence,
loff_t *new_offs
)
{
char * value;
struct open *op;
error_t err = 0;
/* on teste si on a les droits suffisants */
if (! cred)
return EOPNOTSUPP;
/* Ceci ne peut jamais arriver, mais bon. */
if (index > sizeof(lexique)/sizeof(*lexique)-1)
return EINVAL;
value = lexique[index].value;
/* On récupère notre donnée privée */
op = cred->po->hook;
/* voir la page man de lseek() */
switch (whence)
{
case SEEK_SET:
op->offs = offs; break;
case SEEK_CUR:
op->offs += offs; break;
case SEEK_END:
op->offs = strlen (value) - offs; break;
default:
err = EINVAL;
}
/* on devrait tester la validité de op->offs maintenant,
* mais c'est peu important
*/
if (! err)
*new_offs = op->offs;
return err;
}
CC=gcc CFLAGS= -O0 -Wall -ggdb LDFLAGS= -ltrivfs -lfshelp all: lexique lexique: lexique.o $(CC) -o $@ $< $(LDFLAGS) test_begin: lexique settrans -ac foo lexique test_end: foo settrans -fg foo; rm foo lexique.o: lexique.c clean: rm -f *.o *~ distclean: clean rm -f lexique
O_WRITE à la variable globale trivfs_allow_open :
int trivfs_allow_open = O_READ | O_WRITE;Et comme on ajoute le support pour l'écriture, on l'indique en changeant la variable trivfs correspondante :
int trivfs_support_write = 1;Le but de notre translateur est de traduire des mots de l'anglais vers le français (c'est un translateur traducteur). Pour cela, nous allons changer un peu la structure
t_lexique et la variable lexique associée :
struct t_lexique {
char * key;
char * value;
};
struct t_lexique lexique[] = {
{ "accurate", "precis\n" },
{ "beer", "biere\n" },
{ "editor", "vim\n" },
{ "hurd", "hurd\n" },
{ "swimming-pool", "piscine\n" },
{ "wine", "vin\n" },
{ NULL, NULL }
};
Libre à vous ensuite de compléter cette liste.
Il nous reste maintenant à ajouter la fonction d'écriture qui se nomme (si vous avez
bien suivi) trivfs_S_io_write :
error_t trivfs_S_io_write (
trivfs_protid_t cred,
mach_port_t reply,
mach_msg_type_name_t replyPoly,
data_t data,
mach_msg_type_number_t datalen,
loff_t offset,
vm_size_t *amount
)
{
int i;
if (!cred)
return EOPNOTSUPP;
else if (!(cred->po->openmodes & O_WRITE))
return EBADF;
for (i=0; lexique[i].key; i++) {
if (strlen(lexique[i].key)==(datalen-1) &&
!strncmp(lexique[i].key,data,datalen-1))
index = i;
}
*amount = datalen;
return 0;
}
Comme vous le voyez, rien de bien compliqué dans cette fonction. On vérifie simplement que
les "credential" sont là et que le fichier correspondant à notre translateur a bien été
ouvert en écriture. Si c'est le cas, on parcourt notre lexique pour voir si ce qui a été
écrit dans le translateur correspond à l'un des mots que l'on connait. Le cas échéant, on
positionne la variable globale index à une nouvelle valeur.
Quelques remarques :
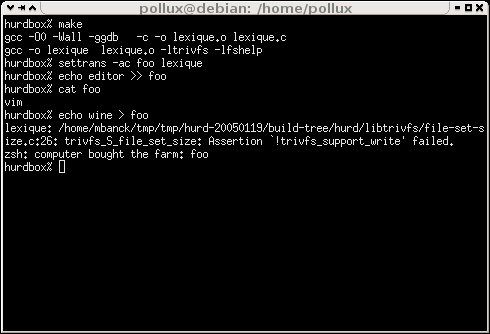
Comme nous venons de le voir, notre translateur n'est pas encore au point (le message
"Computer bought the farm!" est un voisin du fameux SegFault). En effet, tant que l'on
se contente d'ajouter des données (l'opérateur >> ajoute en fichier de ficher),
la séquence d'appels système correspondante est simplement une ouverture en mode
append, une écriture et la fermeture du fichier. Mais lorsque l'on
remplace les données (ce que réalise l'opérateur >), l'ouverture du
fichier se fait avec le mode O_TRUNC, qui donne au fichier une taille de 0.
Dans notre cas, cela n'a pas un grand sens de changer la taille d'un fichier (puisque
nous n'avons pas de fichier dans le sens traditionnel du terme) mais nous devons
tout de même créer la fonction qui est appelée lors d'une ouverture avec O_TRUNC.
Cette fonction se nomme trivfs_S_file_set_size. Et dans notre cas,
nous nous contenterons de ne rien faire, c'est-à-dire que notre fonction renverra
simplement 0 pour indiquer qu'elle s'est déroulée correctement et que l'on a bien
pris note que le fichier avait changé de taille (en gros, on s'en fout complètement,
mais comme cette fonction est appelée, il faut bien l'implémenter).
/* Truncate file. */
error_t
trivfs_S_file_set_size (
trivfs_protid_t cred,
mach_port_t reply,
mach_msg_type_name_t replyPoly,
loff_t new_size
)
{
if (!cred)
return EOPNOTSUPP;
else
return 0;
}
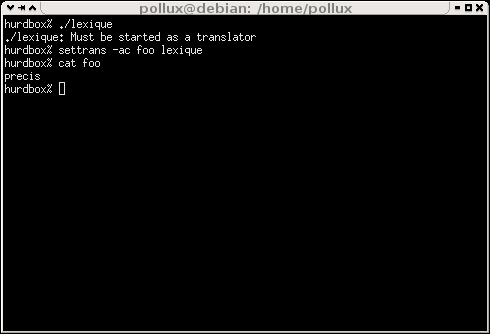
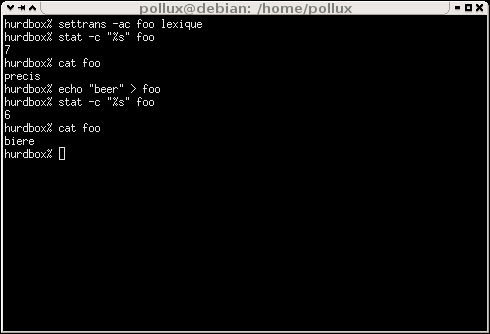
On peut vérifier le meilleur fonctionnement de notre lexique sur le screenshot
[12355346]
Lors de l'appel à settrans, il est possible de passer des paramètres au
translateur. Par exemple le translateur pfinet récupère les paramètres
réseau (adresse ip, masque, etc.) sur la ligne de commande.
Nous allons rester un peu plus modeste, en n'utilisant qu'un seul paramètre. Si ce
paramètre est présent, nous l'interpréterons comme un mot de départ pour le lexique.
Pour cela, il suffit d'ajouter les lignes suivantes au début de notre fonction
main() :
if (argc > 1) {
int i;
for (i=0; lexique[i].key; i++)
if (!strcmp(argv[1],lexique[i].key))
index = i;
}
st_size avec une taille bidon, st_mode avec une valeur constante (fichier en mode 0660).
Pour la taille, nous allons maintenant pouvoir retourner la vraie taille des données
qu'il sera possible de lire, c'est-à-dire la taille du mot traduit (facile à trouver
à partir de l'index courant. Et pour le mode nous utiliserons une nouvelle
variable globale qui contiendra le mode courant current_mode.
Par défaut cette variable aura la même valeur que précédemment :
static int current_mode = (S_IFREG | S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
La fonction trivfs_modify_stat devient alors :
void
trivfs_modify_stat (struct trivfs_protid *cred,
io_statbuf_t *st)
{
/* Mark the node as a read-only plain file. */
st->st_mode &= ~(S_IFMT | ALLPERMS);
st->st_mode |= current_mode;
st->st_size = strlen(lexique[index].value);
}
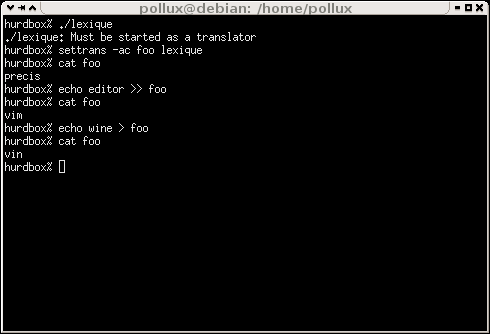
Et on peut vérifier que cette fonction tient bien son rôle sur le screenshot
[123312342]
Maintenant que l'on a une variable qui contient le mode courant, il devient
trivial (!) d'implémenter l'appel système chmod() au travers
de la fonction trivfs_S_file_chmod. Il faut simplement s'assurer
que le fichier garde son type (la partie S_IFMT).
error_t
trivfs_S_file_chmod(
trivfs_protid_t cred,
mach_port_t reply,
mach_msg_type_name_t replyPoly,
mode_t new_mode
)
{
if (!cred)
return EOPNOTSUPP;
current_mode = (current_mode & S_IFMT) | new_mode;
return 0;
}
Encore une fois, on peut vérifier son bon fonctionnement sur le screenshot [66815686]
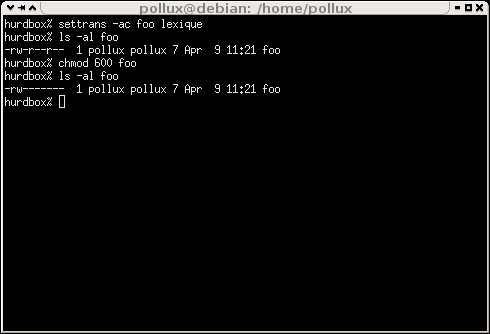
help
help